What is Heterogeneity, Really?
It seems a quite common understanding that unit level ‘heterogeneity’ (i.e. individual differences) when using statistical models reflects some innate characteristic of the individuals. Based on a tiny twitter discussion I thought it might be helpful to demonstrate that such apparent ‘heterogeneity’ can arise very easily as a result of model limitations or choices in how data is structured.
Let’s observe a group of individuals at two occasions, with a space of 1 year between occasions.
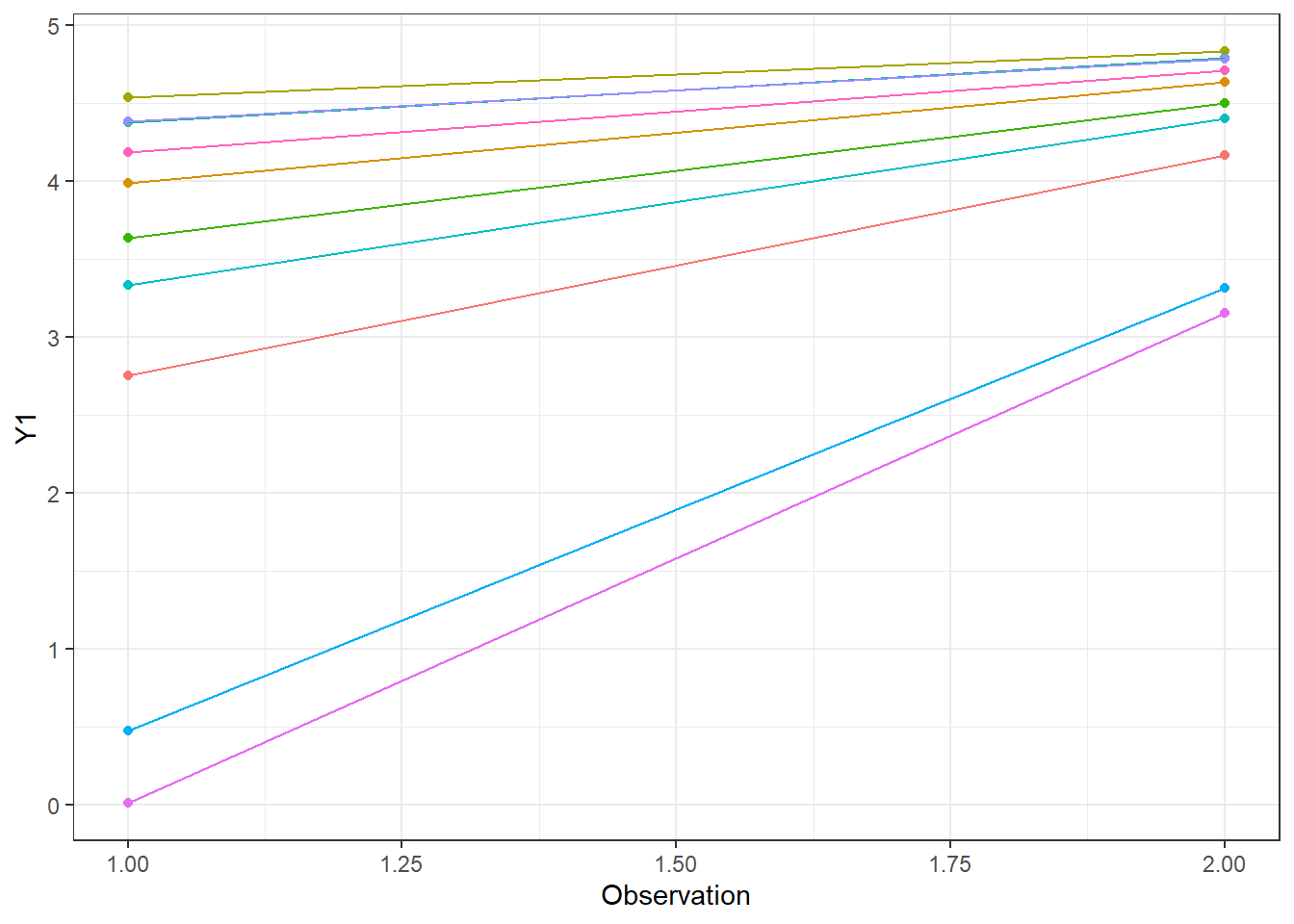
Ok, interesting, we have some heterogeneity in the slope as a function of the individuals’ baseline – those who started lower increased more quickly.
Now let’s plot the same data as a function of the individuals’ age.
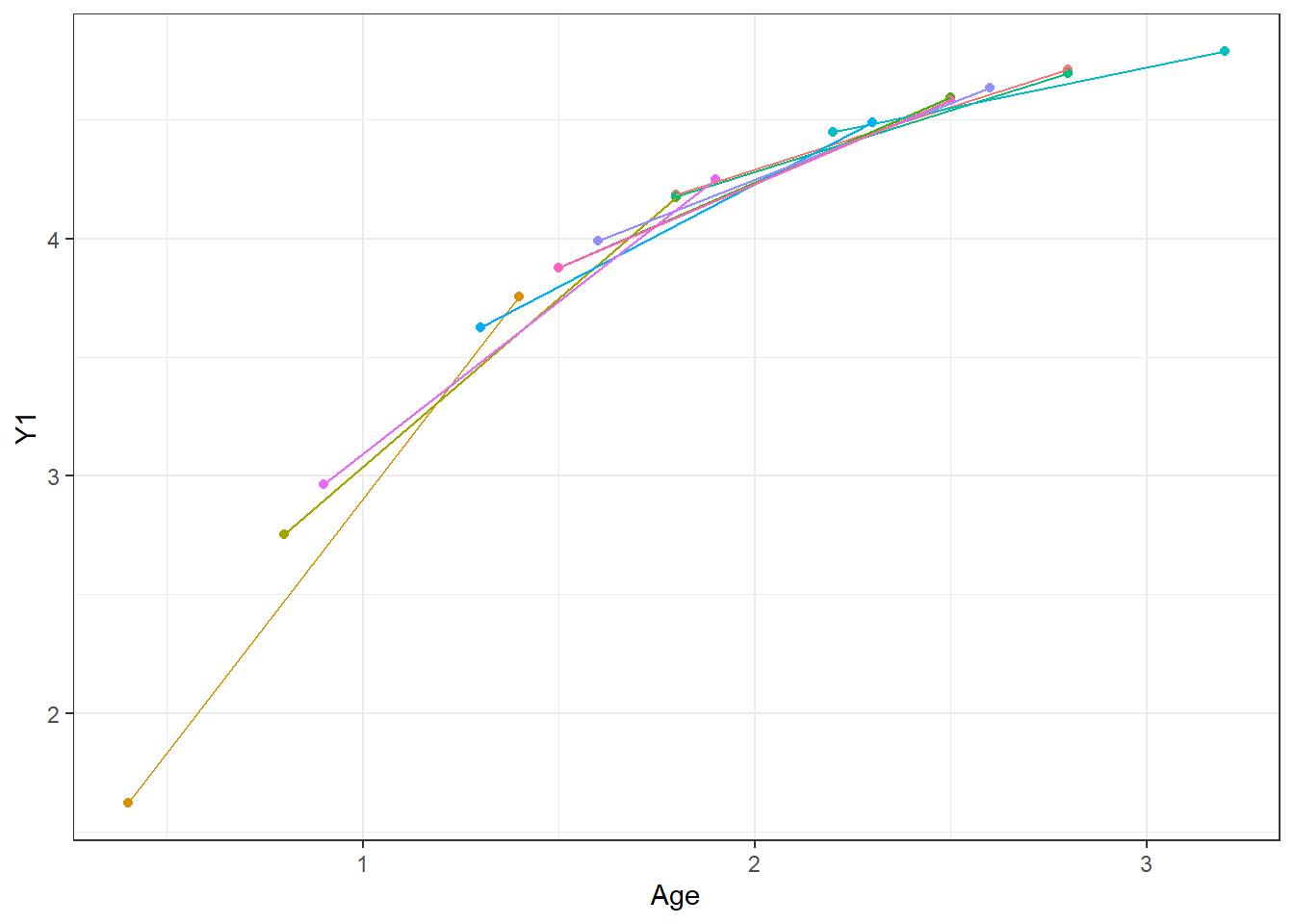
Ahah. Our individuals are not really ‘different’ in some interesting way, they all experience the same pattern of growth, it’s just that growth is nonlinear with respect to age. So, our initial ‘model’ (just a plot in this case) was simply limited in that it didn’t account for this feature of the system we’re interested in – there’s no inherent differences in the system across individuals though!
Charles Driver
Research Scientist
I’m a quantitative psychologist interested in the dynamic systems perspective of human systems.